如何对 PDF 做真正的脱敏
用零信脱敏处理 PDF 文本层、扫描页、图片和批注,导出前检查是否还残留原文。
如何对 PDF 做真正的脱敏
这篇适合你要处理合同、卷宗、报告、扫描 PDF、签署页或图片页 PDF。目标不是在页面上画个黑框,而是导出一个不再暴露敏感信息的副本。
第一步:导入 PDF,并确认它是哪种 PDF
在首页添加 PDF 文件。如果是加密 PDF,先输入正确密码;如果是扫描件或图片页 PDF,后面要重点检查图像里的文字、印章、人脸和二维码。
PDF 常见有三种:
- 可复制文字的 PDF:重点检查文本层。
- 扫描 PDF:重点检查图片像素和 OCR 识别结果。
- 混合 PDF:既有文本层,也有图片、签章、截图或附件。
不要只看页面能不能显示。能显示不代表底层内容已经安全。
第二步:选择要识别的类别
常见 PDF 外发前建议选:
- 姓名、电话号码、邮箱、地址
- 身份证号、出入境证件号
- 单位名称、统一社会信用代码
- 司法案号、发文字号
- 金融账户及卡号、金额、日期
- 印章、人脸、二维码/条形码
如果是合同或法律文书,单位名称、地址、案号、签署页通常比正文更容易漏。
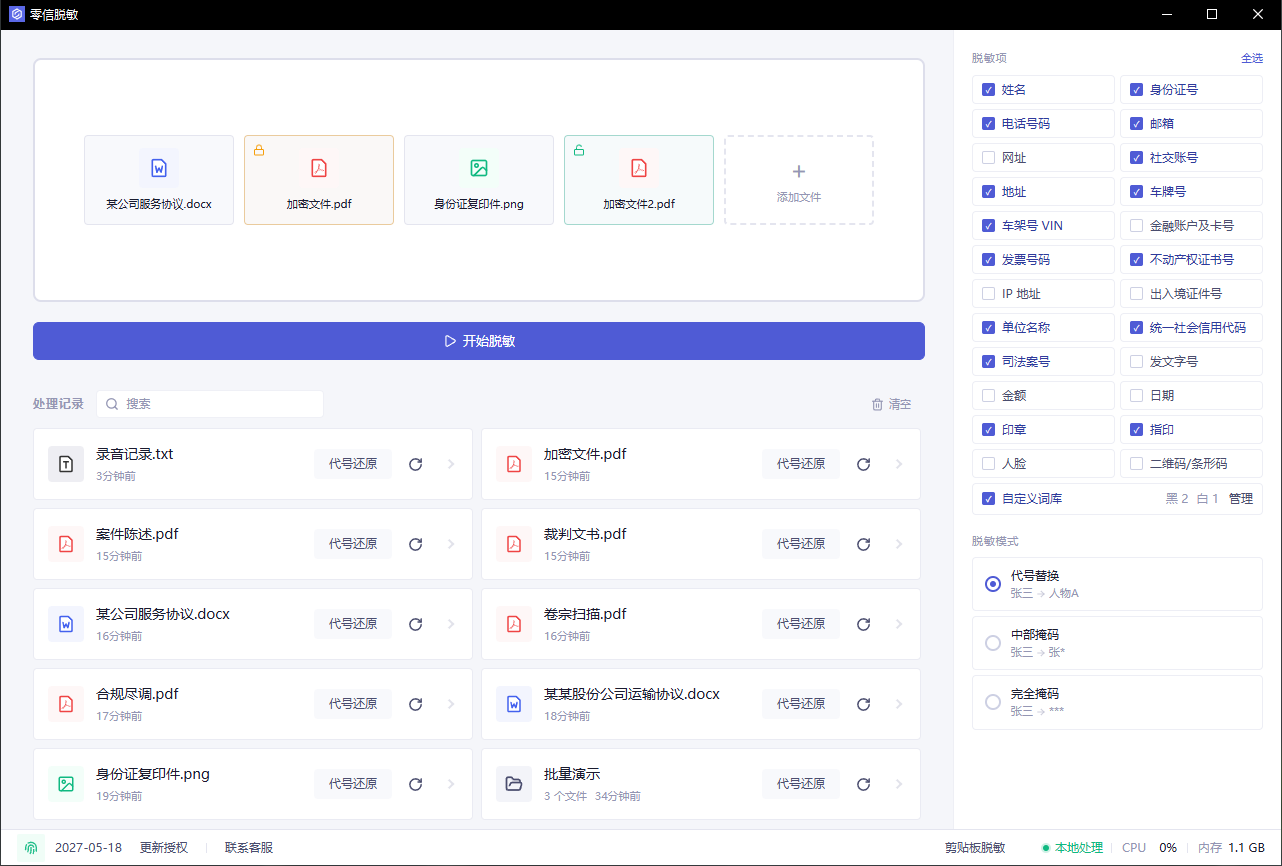
第三步:审阅命中项,不要直接导出
识别完成后,先进入审阅页看右侧命中项。点击命中项可以定位到页面位置。
重点看:
- 同一家公司是否被识别成多个不同名称。
- 页眉页脚是否有客户名、案号或编号。
- 表格、签署页、附件页有没有遗漏。
- 扫描页里的印章、人脸、二维码是否命中。
如果发现公开法规名、公开机构名被误识别,可以忽略;如果发现漏项,手动补标。
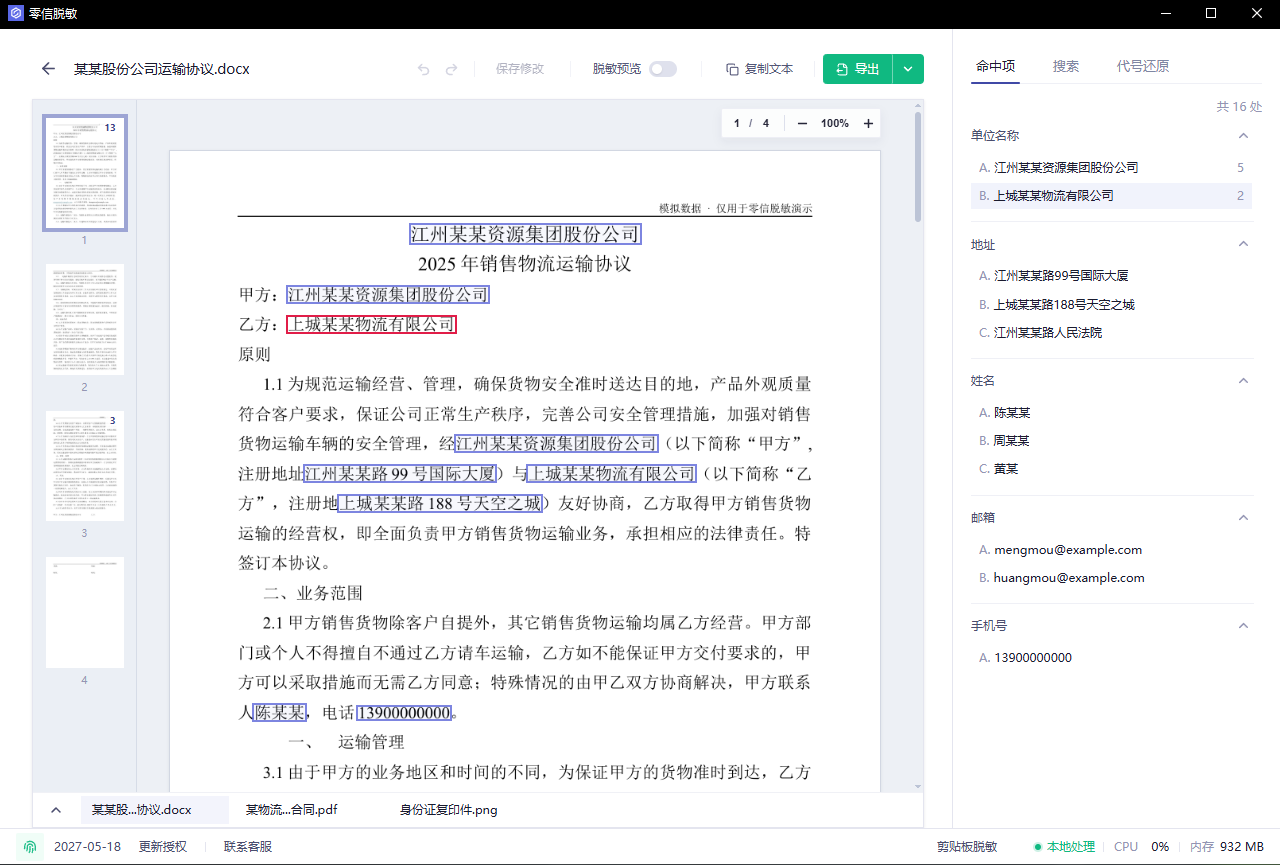
第四步:用搜索查原始关键词
导出前,用搜索查几个你最担心泄露的词。
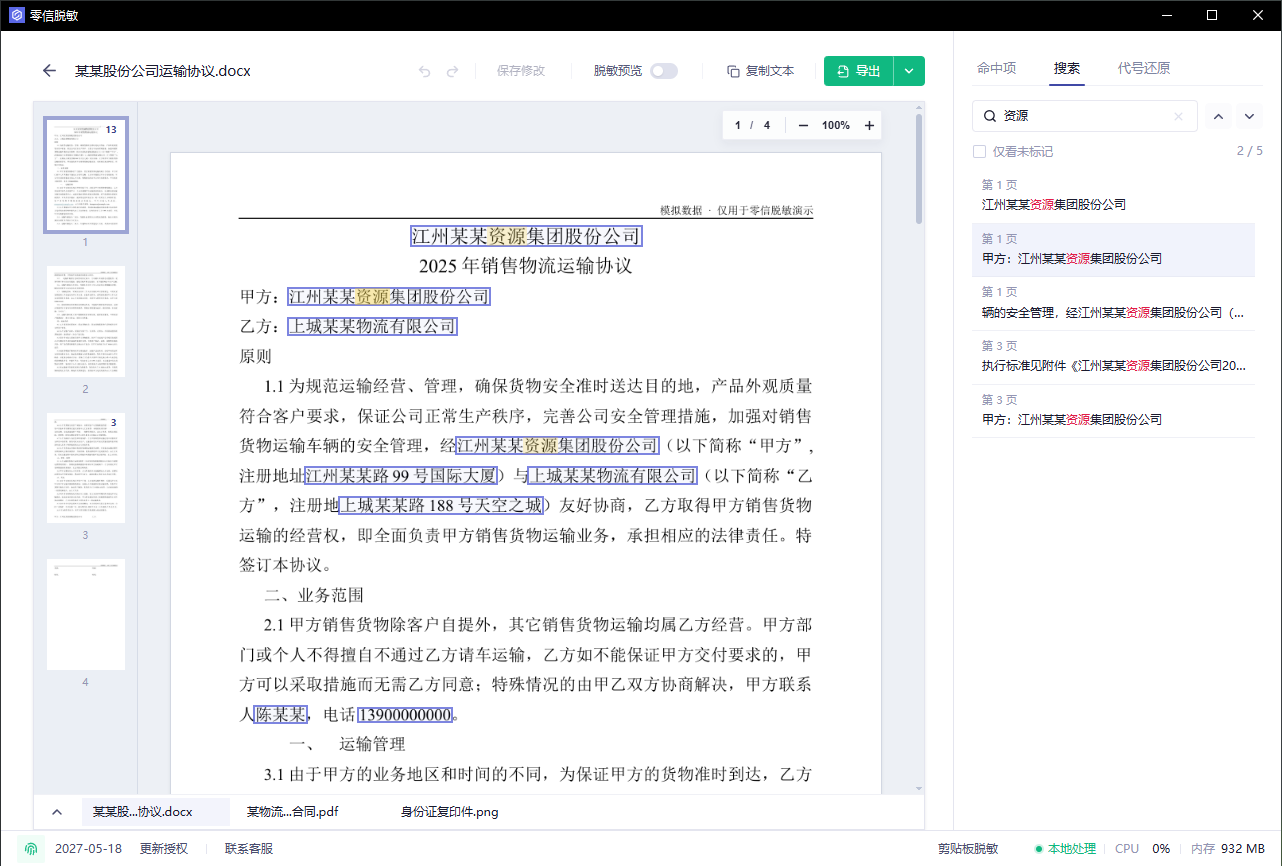
建议搜索:
- 当事人姓名
- 手机号后四位
- 客户简称
- 项目编号
- 案号或合同编号
- 邮箱域名
如果搜索结果里还有未处理内容,先补标再导出。
第五步:打开脱敏预览
切换到脱敏预览,看导出效果是不是符合预期。
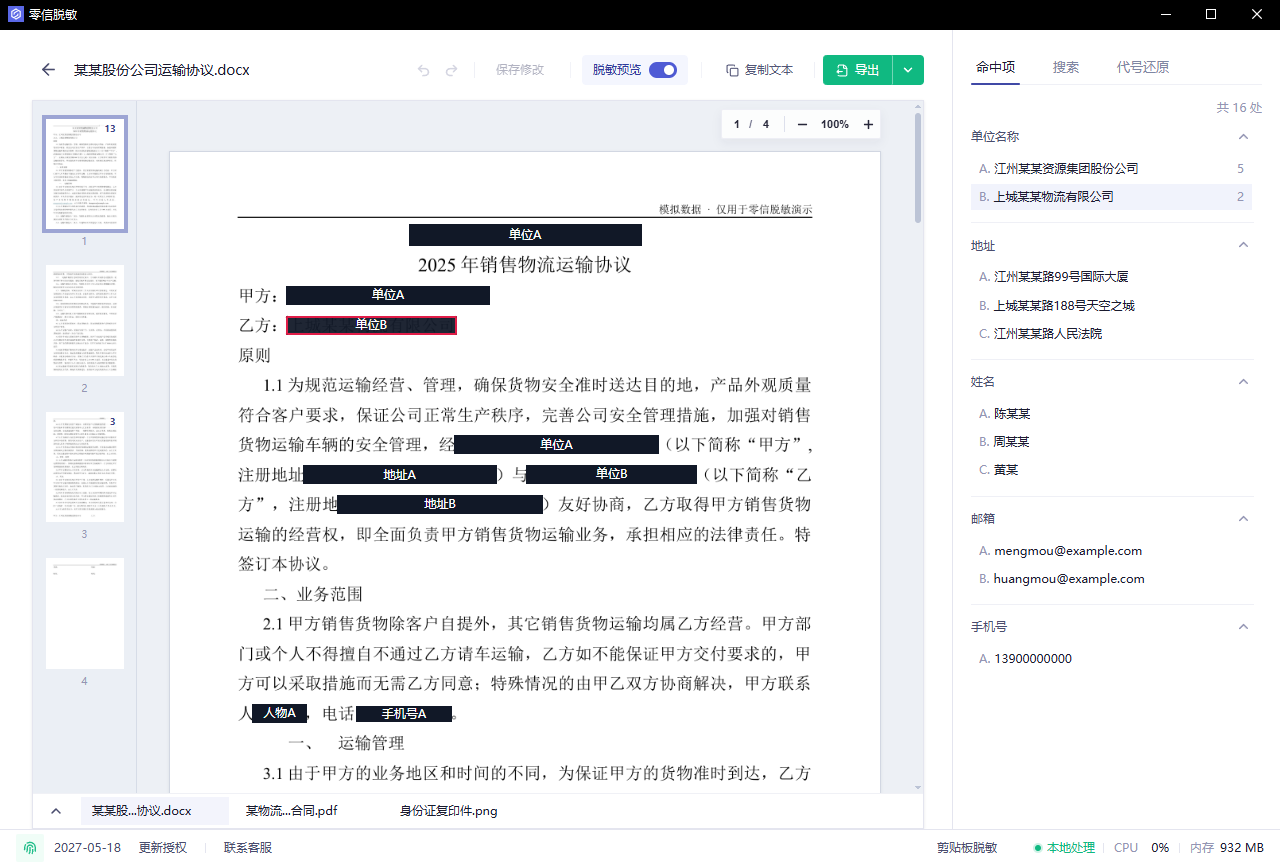
检查这几件事:
- 遮挡或代号位置没有偏移。
- 文字层和图片里的敏感内容都处理了。
- 同一个实体的代号保持一致。
- 文件仍然能正常阅读。
- 页眉页脚、签署页、附件页没有漏。
扫描 PDF 尤其要多翻几页,因为低清、倾斜、印章遮挡会影响识别。
第六步:导出后再验一遍
导出脱敏副本后,不要马上发送。打开导出文件后再做一次快速检查:
- 搜索原始姓名、手机号、公司名。
- 尝试复制被处理位置附近的文本。
- 用另一个 PDF 阅读器打开看一遍。
- 随机翻看签署页、表格页、图片页。
如果这些检查都通过,再发送脱敏副本。不要把原始 PDF 当成处理结果发出去。