把文档发给 AI 前,怎么用零信脱敏先处理
用零信脱敏在本机处理 PDF、Word、Excel、图片和剪贴板文本,再把脱敏后的内容发给 AI。
把文档发给 AI 前,怎么用零信脱敏先处理
这篇适合这种情况:你要把合同、报告、表格、扫描件、聊天记录或网页文字发给 AI,但里面有姓名、电话、公司名、地址、账号或业务信息,不想原样上传。
推荐做法不是把所有内容涂黑,而是先在本机把直接标识符替换成稳定代号,再把脱敏后的文件或文本交给 AI。这样 AI 还能理解上下文。
第一步:导入文件,并选择脱敏类别和脱敏模式
在首页添加要处理的文件。PDF、Word、Excel、CSV、图片、扫描件可以一起放进来;如果只是网页、聊天或邮件片段,可以用剪贴板脱敏处理。
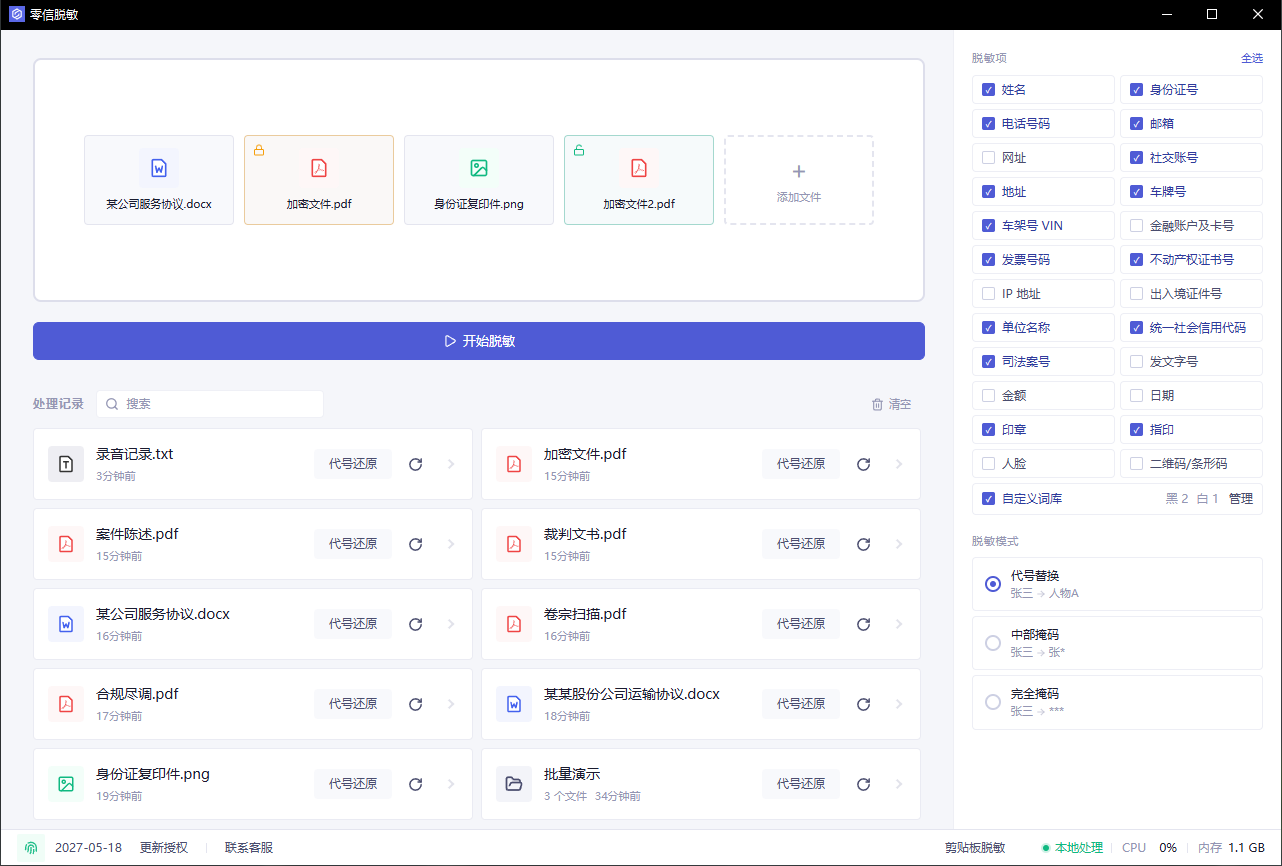
右侧先选本次要识别的类别。AI 前处理通常建议至少选:
- 姓名、电话号码、邮箱、地址
- 单位名称、统一社会信用代码
- 金融账户及卡号、金额、日期
- 印章、人脸、二维码/条形码
- 自定义词库里的客户名、项目名、内部代号
如果你只想隐藏个人信息,不要勾太多业务类别;如果要把材料交给外部 AI,客户名、供应商名、项目名通常也应该处理。
脱敏模式也在开始处理前选。AI 前脱敏多数情况下建议选“代号替换”,例如:
- 张三 -> 人物A
- 某某公司 -> 单位A
- 某地址 -> 地址A
这样比全部打成星号更适合 AI,因为合同关系、人物关系和事件顺序还在。只有证件号、手机号、账号这类不需要语义的内容,才更适合中部掩码或完全掩码。
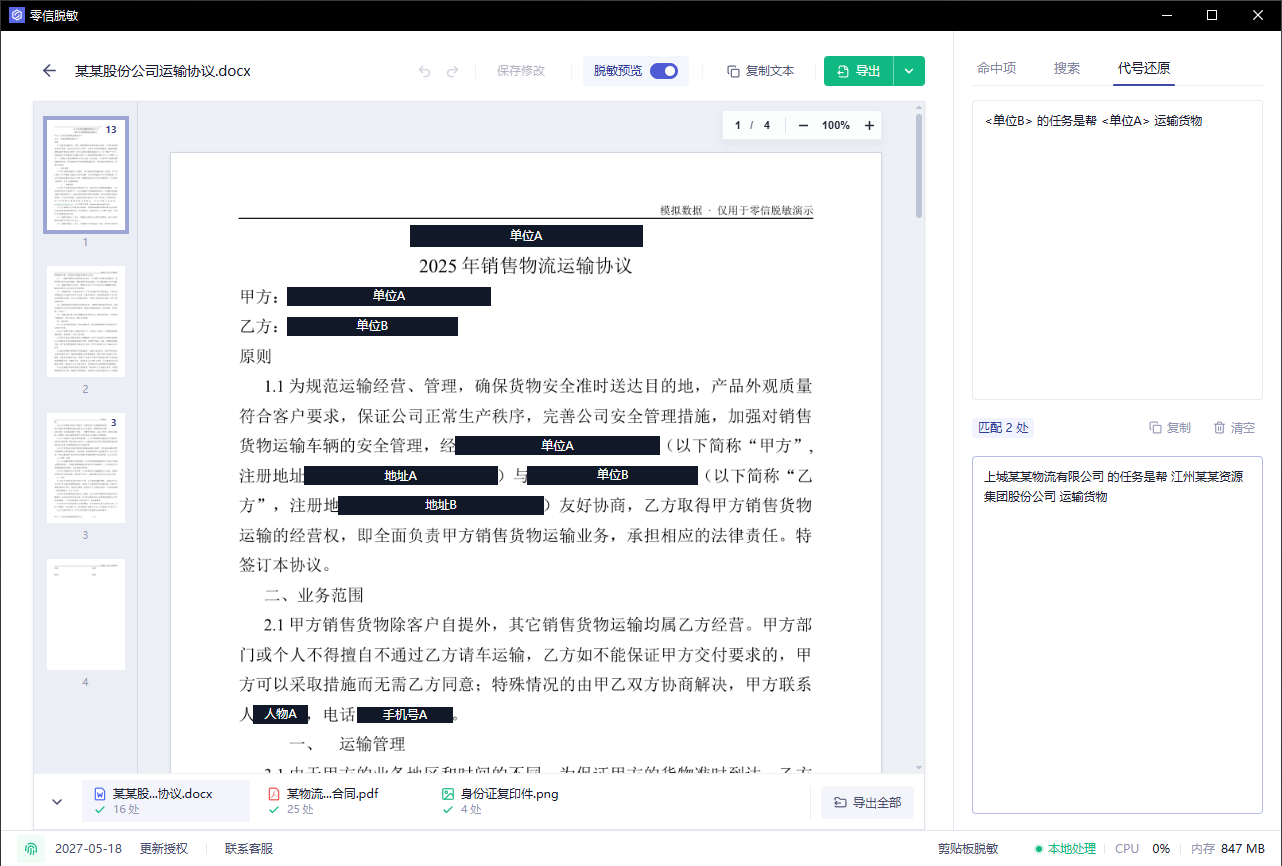
第二步:审阅命中项
识别完成后先看右侧“命中项”。不要直接导出。重点看两个问题:有没有漏掉不该发给 AI 的内容;有没有把公开名称、法规名称或普通业务词误识别。
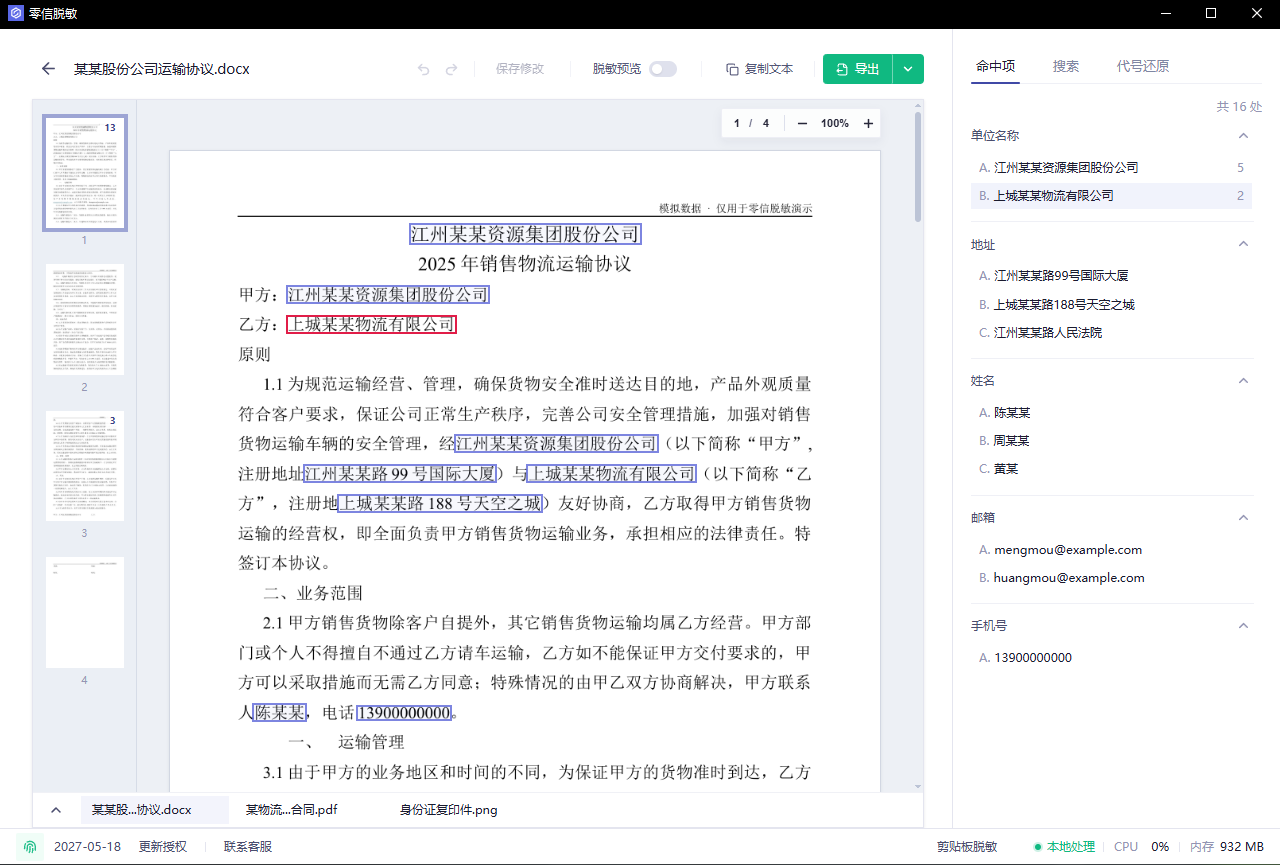
建议按类别看:
- 姓名:是否包含当事人、经办人、联系人
- 单位名称:是否包含客户、供应商、项目公司
- 地址:是否包含办公地址、收货地址、法院地址
- 邮箱/手机号:是否出现在正文、签署页或表格里
看到不需要处理的命中项,就取消或忽略;看到漏掉的内容,再手动补标或加入自定义词库。
第三步:用搜索检查漏项
如果你知道某个客户名、项目名、手机号或内部代号,一定用搜索再查一遍。只看命中列表不够,尤其是长合同、扫描 PDF 和多页附件。
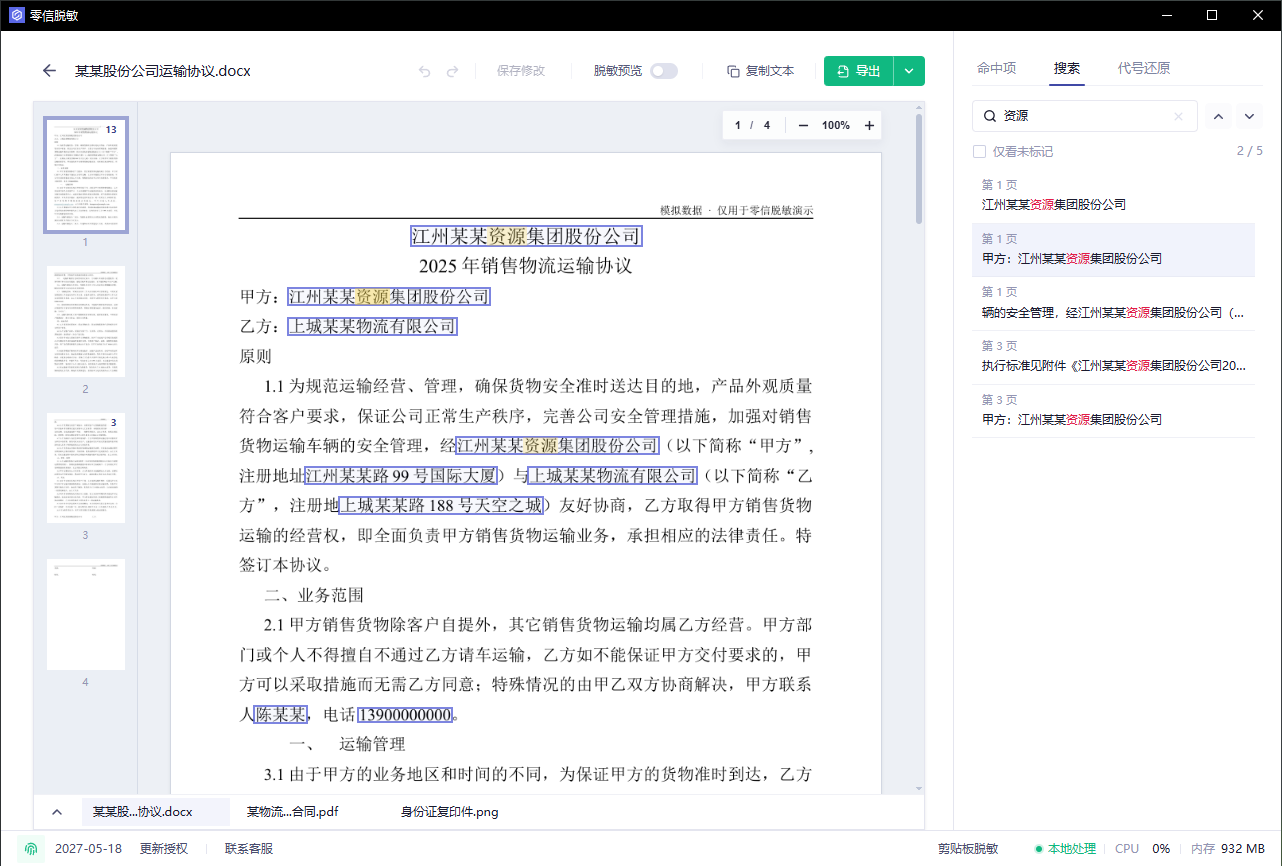
适合搜索的词包括:
- 客户简称、供应商简称
- 项目代号
- 关键联系人姓名
- 手机号后四位
- 邮箱域名
搜索结果里如果还有未标记的敏感内容,先处理再导出。
第四步:打开脱敏预览
导出前打开脱敏预览,确认代号替换后的文本还能读懂。
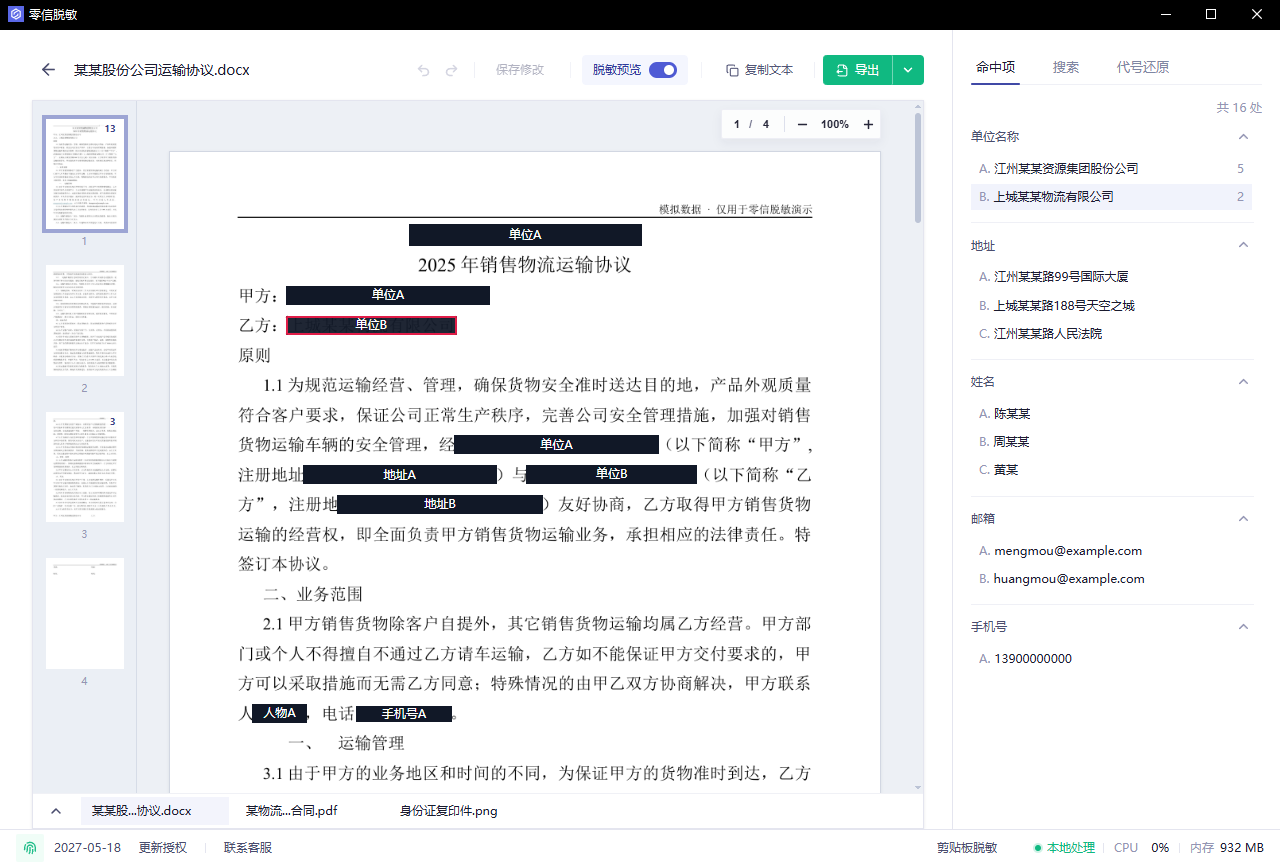
重点检查:
- 同一个人是否始终是同一个代号
- 同一个公司是否始终是同一个代号
- 被遮挡区域有没有偏移
- 页眉、页脚、表格、签署页是否处理到
- 图片、印章、人脸、二维码是否还暴露
如果预览里上下文已经读不通,说明你可能把太多内容完全掩码了。AI 前处理通常保留代号更合适。
第五步:导出后再发给 AI
确认无误后导出脱敏副本,或者复制脱敏后的文本,再粘贴到 AI 工具里。
如果 AI 返回的结果里包含“人物A”“单位B”这类代号,需要还原到原文,可以回到“代号还原”页处理。
最后检查
发送给 AI 前,至少再做一次快速检查:
- 搜索原始姓名、手机号、客户名是否还存在。
- 随机翻几页,看页眉页脚和附件有没有遗漏。
- 确认导出的是脱敏副本,不是原文件。
- 如果材料有保密要求,先按单位内部规则处理,不要只依赖工具。
这套流程的重点是:文件先在本机处理,确认后再发给 AI。