扫描件和图片里的敏感信息怎么脱敏
用零信脱敏处理扫描 PDF、图片、截图和证照页,检查图片文字、印章、人脸、二维码和手写内容。
扫描件和图片里的敏感信息怎么脱敏
这篇适合你要处理扫描 PDF、证照图片、合同签署页、聊天截图、系统截图或图片页 PDF。这里的重点不是替换文本,而是确认图片里看到的敏感内容也被处理掉。
第一步:导入扫描件或图片
在首页添加扫描 PDF、PNG、JPG 或其他图片文件。如果同一批材料里既有 PDF,也有图片和 Word,可以一起导入,方便统一审阅。
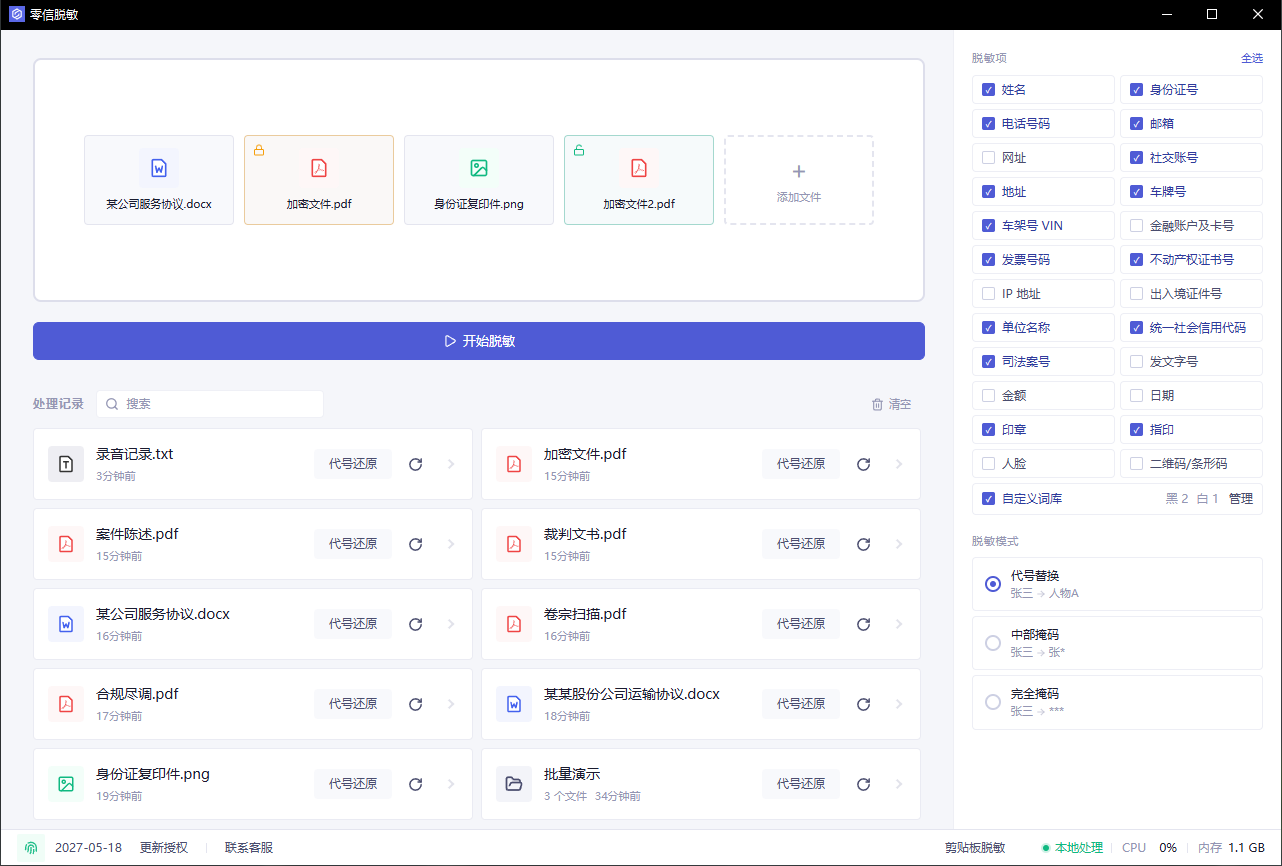
扫描件和图片建议勾选:
- 姓名、电话号码、邮箱、地址
- 身份证号、证件编号、车牌号
- 单位名称、统一社会信用代码
- 印章、人脸、二维码/条形码
- 自定义词库里的客户名、项目名、内部编号
如果是证照、签署页、报销材料或病历报告,印章、人脸、二维码和编号要重点看。
第二步:先判断它是不是图片页
很多 PDF 看起来像普通文档,但页面本身其实是一张扫描图。判断方法很简单:
- 鼠标选不中文字,通常是扫描页。
- 放大后文字边缘像图片,通常是扫描页。
- 搜索不到页面里的文字,通常是扫描页。
- 页面里有盖章、签名、手写备注,通常需要按图片处理。
扫描页不能只靠文本替换。图片上的姓名、电话、印章、人脸和二维码,必须在图像层面处理。
第三步:审阅命中项
识别完成后,看右侧“命中项”。扫描件比普通文档更容易漏识别,所以不要只看列表数量,要点到页面上确认位置。
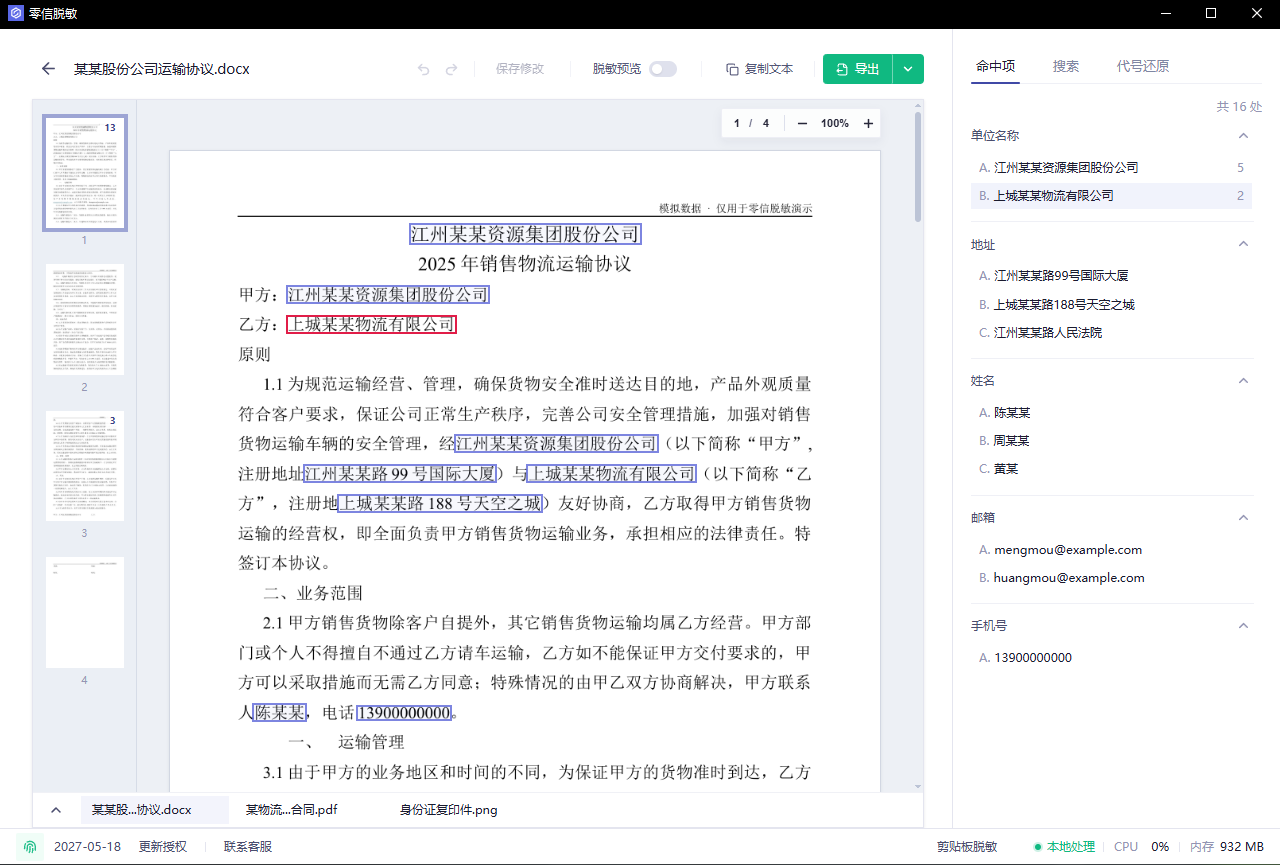
重点看这些地方:
- 首页、尾页、签字盖章页。
- 表格里的联系人、电话、地址、账号。
- 页面角落的编号、水印、二维码。
- 证照图片上的姓名、号码、地址、人脸。
- 手写备注、签名、指印和印章。
如果图片不清晰、页面倾斜或有水印,识别结果可能不完整,需要手动补标。
第四步:用搜索检查已知文字
如果你知道材料里一定有某个姓名、手机号、客户名或证件号,用搜索查一遍。
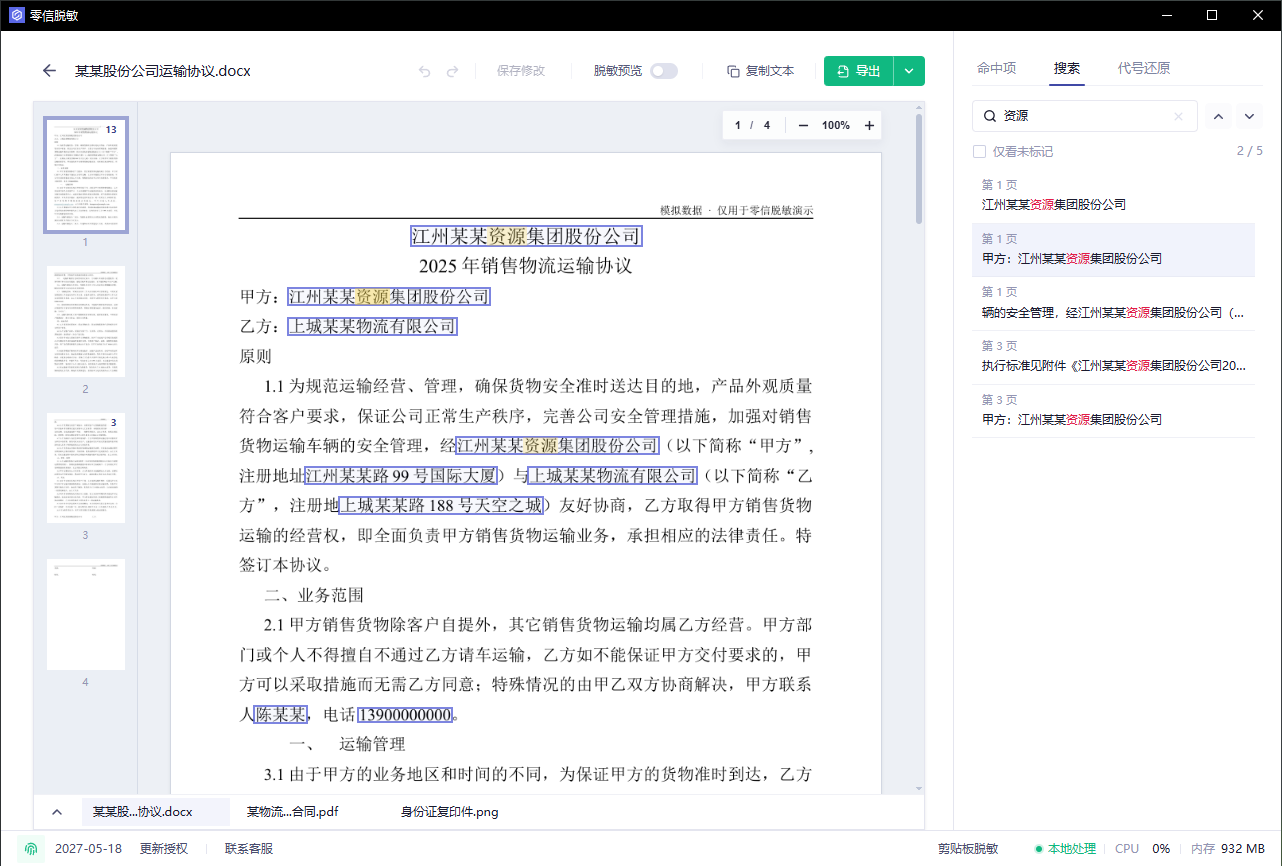
搜索能帮你发现两类问题:
- OCR 识别到了文字,但没有被选为脱敏项。
- 同一个词在不同页面出现,有的处理了,有的漏了。
如果搜索不到,不代表一定安全。扫描件里的低清文字、手写内容、印章和二维码,仍然需要人工看页面。
第五步:看脱敏预览
导出前打开脱敏预览,确认遮挡或替换位置没有偏移。
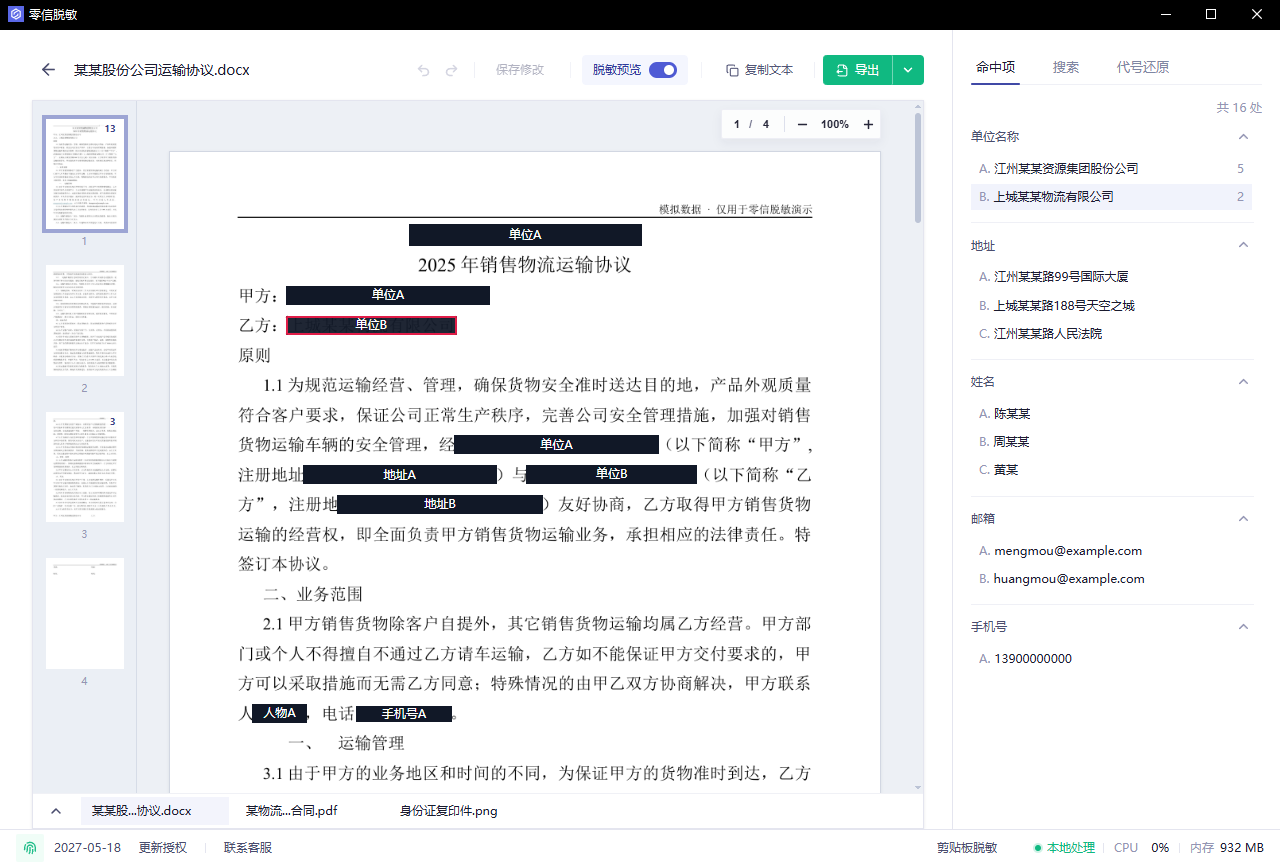
扫描件预览重点检查:
- 遮挡区域是否盖住完整文字。
- 人脸、二维码、印章是否还可识别。
- 页眉页脚和角落编号有没有遗漏。
- 表格线、印章、背景纹理是否影响遮挡效果。
- 同一份材料里的同类信息处理方式是否一致。
第六步:导出后逐页抽查
扫描件和图片材料不要只抽查第一页。建议至少检查:
- 每份文件的第一页和最后一页。
- 所有签字盖章页。
- 所有证照页、二维码页、截图页。
- 图片质量最差、最倾斜、最拥挤的页面。
如果材料要发给 AI 或外部系统,确认导出的是脱敏副本,不要把原图或原 PDF 一起上传。